Search ConsoleのCSVデータをSQLで集計する方法|Python・BigQuery・ブラウザツール別に解説
Search Consoleの管理画面では、1,000行までしかデータをエクスポートできません。月次比較やクロス集計をしようとすると、すぐに限界にぶつかります。
この記事では、Search ConsoleからエクスポートしたCSVデータをSQLで柔軟に集計する方法を3つ紹介します。Pythonスクリプトで手元のCSVに直接SQLを実行する方法、BigQueryで全量データを本格分析する方法、そしてSQLを書かずにブラウザ上で集計する方法です。
Search ConsoleのCSVをSQL集計する3つの方法
Search ConsoleのCSVデータをSQLで集計するアプローチは、大きく3つあります。それぞれの特徴を比較表にまとめました。
| 方法 | セットアップ | コスト | データ量 | SQL知識 | おすすめシーン |
|---|---|---|---|---|---|
| Python(DuckDB) | pip install duckdb のみ | 無料 | CSV単位(数万行) | 必要 | 手元のCSVをサッと集計したいとき |
| BigQuery | GCPプロジェクト作成+連携設定 | 従量課金(無料枠あり) | 全量データ(制限なし) | 必要 | 1,000行制限を超えた全件分析、GA4との統合 |
| ブラウザツール | 不要(ブラウザで開くだけ) | ツールによる | CSV単位 | 不要 | SQLを書かずにGUIで集計したいとき |
まずは手軽に試せるPythonから解説します。
PythonでSearch Console CSVをSQL集計する(手軽度★★★)
PythonのDuckDBライブラリを使うと、CSVファイルに対して直接SQLクエリを実行できます。テーブル設計もデータベースサーバーも不要です。
DuckDBのインストールと基本操作
ターミナルで以下を実行するだけで準備完了です。
pip install duckdb pandas
Search Consoleからダウンロードしたzipを展開すると、以下の6種類のCSVファイルが含まれています。
| ファイル名 | 内容 | 主な用途 |
|---|---|---|
Queries.csv | 検索クエリ別のパフォーマンス | キーワードの順位・CTR分析 |
Pages.csv | ページ別のパフォーマンス | ページごとのクリック数・表示回数 |
Countries.csv | 国別のパフォーマンス | 地域別トラフィック分析 |
Devices.csv | デバイス別のパフォーマンス | モバイル・デスクトップ比較 |
Dates.csv | 日付別のパフォーマンス | 期間別のトレンド分析 |
SearchAppearance.csv | 検索結果での表示タイプ | リッチリザルト・AMP表示分析 |
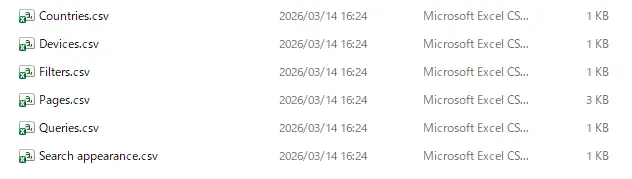
各CSVの列構成は共通で、Top queries(またはTop pages等のディメンション列)、Clicks、Impressions、CTR、Position の5列です。
CSVを読み込んでSQLを実行する基本形はこれだけです。
import duckdb
result = duckdb.sql("""
SELECT *
FROM read_csv_auto('Queries.csv')
LIMIT 10
""")
print(result)
read_csv_auto() はCSVのヘッダーや型を自動推定します。Search ConsoleのCSVはUTF-8(BOM付き)で出力されますが、DuckDBはBOMを自動的に処理するので、文字化けの心配はありません。
コピペで使えるSearch Console集計クエリ集
ここからは、実務で使う頻度が高いクエリをそのまま貼り付けて使える形で紹介します。
クエリ別パフォーマンス — クリック数が多い順
import duckdb
df = duckdb.sql("""
SELECT
"Top queries" AS query,
Clicks AS clicks,
Impressions AS impressions,
CTR AS ctr,
Position AS avg_position
FROM read_csv_auto('Queries.csv')
ORDER BY Clicks DESC
LIMIT 50
""").df()
print(df)
.df() を付けるとpandasのDataFrameとして結果を取得できます。Excel出力やグラフ化との連携が楽になります。
CTR改善候補の抽出 — 表示回数が多いのにクリック率が低いクエリ
施策の優先度を決めるときに役立つクエリです。「表示はされているのにクリックされていない」キーワードを見つけます。
import duckdb
df = duckdb.sql("""
SELECT
"Top queries" AS query,
Clicks AS clicks,
Impressions AS impressions,
CTR AS ctr,
Position AS avg_position
FROM read_csv_auto('Queries.csv')
WHERE Impressions >= 100
AND CTR < 0.02
ORDER BY Impressions DESC
""").df()
print(df.to_string(index=False))
表示回数100以上・CTR 2%未満のクエリを抽出しています。閾値はサイト規模に合わせて調整してください。
ページ別パフォーマンス — ディレクトリ単位でグルーピング
ブログ記事全体の傾向を把握したい場合など、URLのディレクトリ単位で集計すると全体像が見えます。
import duckdb
df = duckdb.sql("""
SELECT
regexp_extract("Top pages", '^https?://[^/]+(/[^/]+/)', 1) AS directory,
SUM(Clicks) AS total_clicks,
SUM(Impressions) AS total_impressions,
ROUND(SUM(Clicks) * 1.0 / SUM(Impressions), 4) AS avg_ctr
FROM read_csv_auto('Pages.csv')
WHERE regexp_extract("Top pages", '^https?://[^/]+(/[^/]+/)', 1) IS NOT NULL
GROUP BY directory
ORDER BY total_clicks DESC
""").df()
print(df)
注意: このパターンは https://example.com/blog/ のように第1階層にスラッシュが付くURLを想定しています。https://example.com/page(末尾スラッシュなし)のようなURLはマッチせず、NULLとして扱われます(上のWHERE句でNULL行は除外しています)。サイトのURL構造に合わせて正規表現を調整してください。
月次CSVを結合して期間比較する
Search Consoleから月ごとにCSVをダウンロードしている場合、それらを UNION ALL で結合して前月比を出せます。
ファイル名を 2026-01/Queries.csv、2026-02/Queries.csv のように月別ディレクトリで管理している前提です。
import duckdb
df = duckdb.sql("""
WITH monthly AS (
SELECT '2026-01' AS month, *
FROM read_csv_auto('2026-01/Queries.csv')
UNION ALL
SELECT '2026-02' AS month, *
FROM read_csv_auto('2026-02/Queries.csv')
)
SELECT
"Top queries" AS query,
SUM(CASE WHEN month = '2026-01' THEN Clicks ELSE 0 END) AS clicks_jan,
SUM(CASE WHEN month = '2026-02' THEN Clicks ELSE 0 END) AS clicks_feb,
SUM(CASE WHEN month = '2026-02' THEN Clicks ELSE 0 END)
- SUM(CASE WHEN month = '2026-01' THEN Clicks ELSE 0 END) AS diff
FROM monthly
GROUP BY "Top queries"
ORDER BY diff DESC
LIMIT 30
""").df()
print(df)
クリック数が前月から大きく伸びたキーワードが上位に並びます。逆に ORDER BY diff ASC にすれば、減少が大きいキーワードを把握できます。
ワイルドカードで一括読み込みする方法
ディレクトリ内のCSVをまとめて読み込む場合は、glob パターンが使えます。ただし、この方法だとどのファイルが何月分かをSQL内で判別できないため、ファイル名に月を含めておく必要があります。
import duckdb
df = duckdb.sql("""
SELECT *
FROM read_csv_auto('monthly/Queries_*.csv', filename=true)
LIMIT 10
""").df()
print(df)
filename=true を指定すると、どのファイルから読み込まれた行かを示す filename 列が追加されます。
BigQueryでSearch Consoleデータを本格分析する(手軽度★☆☆)
1,000行の制限を根本的に解消したい場合、BigQueryへの一括データエクスポートが有効です。Search Consoleの全量データが日次でBigQueryに自動連携されます。
BigQuery一括エクスポートの設定手順
- Google Cloud Consoleでプロジェクトを作成(既存プロジェクトでも可)
- Search Consoleの「設定」→「一括データ エクスポート」を開く
- BigQueryプロジェクトを選択し、データセット名を指定
- 「エクスポートを開始」をクリック
初回のデータ反映には約48時間かかります。以後は日次で自動的にデータが蓄積されます。
エクスポートされると、BigQuery上に以下のテーブルが作成されます。
searchdata_site_impression— サイト単位の検索データsearchdata_url_impression— URL単位の検索データ
BQで使えるSearch Console集計SQLサンプル
以下のクエリはBigQuery専用です。DuckDBでは SAFE_DIVIDE が使えないため、DuckDBで同等の処理をする場合は CASE WHEN SUM(impressions) = 0 THEN 0 ELSE SUM(clicks) * 1.0 / SUM(impressions) END のように書き換えてください。
クエリ別パフォーマンス集計
-- BigQuery専用(SAFE_DIVIDEはBigQuery固有の関数)
SELECT
query,
SUM(clicks) AS total_clicks,
SUM(impressions) AS total_impressions,
ROUND(SAFE_DIVIDE(SUM(clicks), SUM(impressions)), 4) AS ctr,
ROUND(SUM(impressions * position) / SUM(impressions), 1) AS weighted_avg_position
FROM
`your-project.searchconsole.searchdata_site_impression`
WHERE
data_date BETWEEN '2026-02-01' AND '2026-02-28'
AND query IS NOT NULL -- 匿名化クエリを除外
GROUP BY
query
ORDER BY
total_clicks DESC
LIMIT 100
query IS NOT NULL で匿名化クエリを除外しています。この行を外すと、合計値にはプライバシー保護で非表示になったクエリの数値も含まれます。
平均掲載順位は、単純平均ではなく表示回数で加重平均しています。表示回数が1回のロングテールキーワードと、1万回表示されるメインキーワードを同じ重みで平均すると実態から乖離するためです。
デバイス×国 のクロス集計
Search Consoleの管理画面では、「デバイス別」と「国別」を同時にフィルタできません。BigQueryなら自由にクロス集計できます。
-- BigQuery専用
SELECT
device,
country,
SUM(clicks) AS total_clicks,
SUM(impressions) AS total_impressions
FROM
`your-project.searchconsole.searchdata_site_impression`
WHERE
data_date BETWEEN '2026-02-01' AND '2026-02-28'
GROUP BY
device, country
ORDER BY
total_clicks DESC
従量課金を抑えるコツ
BigQueryはスキャンしたデータ量に応じて課金されます(執筆時点で毎月1TBまでは無料。最新の料金体系はGoogle Cloud公式サイトで確認してください)。コストを抑えるポイントは3つあります。
| 対策 | 効果 | 実装方法 |
|---|---|---|
SELECT * を避ける | スキャン量の大幅削減 | 必要な列だけ指定(例: SELECT query, clicks, impressions) |
data_date で期間を絞る | パーティション読み込みに限定 | WHERE句で日付範囲を指定(テーブルは日付分割済み) |
| 実行前にスキャン量確認 | 予期しない大規模処理を防止 | エディタ右上の推定値で判断後、必要に応じてクエリ見直し |
SQLを書かずにブラウザで集計する方法(手軽度★★★)
SQLを書かなくても、ブラウザ上でCSVを読み込んでGUI操作で集計できるツールがあります。
ブラウザ完結型CSV分析ツールの使い方
LeapRows(※筆者開発ツール)のようなブラウザ完結型のCSV分析ツールを使うと、CSVファイルをドラッグ&ドロップするだけでピボット集計やフィルタリングができます。
データはブラウザ内で処理され、外部サーバーには送信されません。クライアントの検索データなど、機密性の高いデータを扱う場合に安心です。
操作手順はシンプルです。
- ツールにアクセスし、Search ConsoleのCSVファイルをアップロードする
- 「Analyze」画面でピボットテーブルの行・列・値を指定する
- フィルタで条件を絞り込む(例: 表示回数100以上)
- 結果をCSVとしてダウンロードする
SQLを書く必要がないので、非エンジニアのマーケティング担当者でもすぐに使えます。
Search Analytics for Sheetsで1,000行制限を超える
Googleスプレッドシートのアドオン「Search Analytics for Sheets」を使うと、Search ConsoleのCSVエクスポートでは取得できない1,000行超のデータを取得できます(無料プランで最大25,000件、有料プランでは10万件以上に対応。最新の仕様はアドオンの公式ページで確認してください)。
導入手順:
- Googleスプレッドシートを開く
- 「拡張機能」→「アドオン」→「アドオンを取得」
- 「Search Analytics for Sheets」を検索してインストール
- Search Console権限のあるGoogleアカウントで認可する
サイドバーからサイト・期間・検索タイプを選択し、「Request Data」をクリックするとデータがシートに展開されます。
「Backups」タブで日次または月次の自動エクスポートを設定しておくと、毎回手動でCSVをダウンロードする手間が省けます。蓄積されたデータをCSVに書き出し、先述のPythonスクリプトで集計するワークフローも組めます。
Search Console CSVを扱う前に知っておくべき3つの落とし穴
ここまでの集計テクニックを使う前に、Search ConsoleのCSVデータが持つ構造的な制約を理解しておく必要があります。これを知らないと、集計結果の解釈を誤ります。
匿名化クエリ — CSVの合計値≠実際の合計値
Search Consoleは、プライバシー保護のために検索クエリの一部を匿名化・除外しています。
「Queries.csv」に含まれるクエリのクリック数・表示回数を合計しても、「Dates.csv」の合計値とは一致しません。ページによっては50〜80%のクエリデータが欠損しているケースもあります。
対策としては、合計値は「Dates.csv」の数値を正とすることです。クエリ別の内訳は「全体の中の見えている部分」として扱います。KPIレポートで合計値を報告する場合は、Dates.csvの合計を使ってください。
1,000行打ち切り — ロングテールが消える
Search ConsoleのCSVエクスポートは、各タブ(クエリ・ページ・国・デバイス・日付)ごとに上位1,000行までしか出力されません。
サイト規模が大きいほど、ロングテールキーワードや個別ページのデータが欠落します。全件データが必要な場合は、以下のいずれかで対応してください。
| 方法 | 最大件数 | セットアップ | 自動化 |
|---|---|---|---|
| Search Analytics for Sheets | 25,000件(無料)/ 10万件〜(有料) | アドオンインストール | ○ 月次自動化可能 |
| Search Console API | 全件取得 | プログラミング必要 | ○ スクリプトで自動化 |
| BigQuery一括エクスポート | 全量データ | GCP設定 | ○ 日次自動連携 |
文字化け — ExcelでUTF-8 CSVを正しく開く方法
Search ConsoleのCSVはUTF-8で出力されます。Windowsの場合、Excelで直接ダブルクリックして開くと日本語が文字化けすることがあります。
| 環境・方法 | 文字化けの有無 | 手順 |
|---|---|---|
| Excel 2019以降(Windows) | ◎ 対応可 | 「データ」→「テキストまたはCSVから」→エンコード「UTF-8」確認 |
| Excelダブルクリック | × 文字化け | ◎ 非推奨 |
| Python DuckDB/pandas | ◎ 自動認識 | UTF-8を自動認識、設定不要 |
集計結果を定期レポートに自動反映する(手軽度★★☆)
ここまでの方法で一度きりの集計はできますが、月次レポートを毎回手作業で作るのは非効率です。定期レポートを自動化する方法を2つ紹介します。
Looker StudioにSearch Consoleを直接接続する
Looker Studio(旧Googleデータポータル)はSearch Consoleのコネクタを標準搭載しています。一度ダッシュボードを作れば、アクセスするたびにデータが更新されます(キャッシュの関係で最新データの反映にタイムラグがある場合があります)。
- Looker Studioにアクセスし、新しいレポートを作成
- データソースとして「Search Console」を選択
- サイトを選び、「サイトのインプレッション」または「URLのインプレッション」を選択
- グラフやテーブルを配置して完成
ただしLooker Studio経由のSearch Consoleデータにも行数の上限があります(執筆時点でページ×キーワードの組み合わせは50,000行以下)。大規模サイトではBigQueryをデータソースにしたほうが正確です。
Pythonスクリプトを定期実行する
毎月のCSVダウンロードとSQL集計を自動化したい場合、Search Console APIとPythonスクリプトを組み合わせる方法があります。
概要としては、google-auth と google-api-python-client でAPI認証を行い、searchAnalytics().query() でデータを取得してCSVに保存、その後DuckDBで集計SQLを実行して結果をCSV/Excel出力するという流れになります。
詳細な実装はGoogle公式ドキュメントの「Search Console API」を参照してください。cron(Linux/Mac)やタスクスケジューラ(Windows)で月次実行を設定すれば、毎月の手動作業をゼロにできます。
まとめ
Search ConsoleのCSVデータをSQLで集計する方法は、手軽さの順に以下の3つです。
- Python(DuckDB):
pip install duckdbだけで始められる。CSVファイルに直接SQLを実行し、結果をpandas DataFrameで受け取れる。まず試すならこの方法 - ブラウザツール: SQL不要でGUI操作だけで集計できる。データがサーバーに送信されないブラウザ完結型のツール(LeapRows(※筆者開発ツール)など)なら、機密データも安心して扱える
- BigQuery: 1,000行制限を完全に解消し、全量データの分析やGA4との統合が可能。セットアップに手間はかかるが、大規模サイトの本格分析には必須
集計の前に押さえておくべき注意点は3つです。
- 匿名化クエリ: CSVのクエリ別合計値は実際の合計値より少ない。合計を報告するなら「Dates.csv」の数値を使う
- 1,000行打ち切り: ロングテールが含まれない。全件が必要ならSearch Analytics for Sheets・API・BigQueryで取得する
- 文字化け: ExcelでCSVを開くときは「データ」タブから読み込む。Pythonなら自動処理される