AhrefsのCSVを結合して分析する方法|ノーコードで競合データを可視化
Ahrefsのデータは、ダッシュボード上で見るだけでは活用しきれません。
競合サイトとのキーワード順位を時系列で比較したい。複数ドメインのトラフィック推移を並べて見たい。自社にない競合の獲得キーワードを洗い出したい——こうした分析には、Ahrefsから定期的にCSVをエクスポートして、結合して、集計するプロセスが必要です。
この記事では、AhrefsのCSVを結合して競合分析する方法を3つ紹介します。ブラウザだけで完結する方法から、ExcelのPower Query、Pythonまで。結合前にやるべきエクスポートの準備と、結合後の実践的な分析パターンもまとめました。
AhrefsのCSVを結合して競合分析する3つの方法
AhrefsのCSVを結合する方法は、大きく3つあります。どれを選ぶかは「どこまで自動化したいか」と「チームメンバーも使えるか」で決まります。
方法の比較
| 方法 | 手軽度 | 柔軟性 | 自動化 | おすすめシーン |
|---|---|---|---|---|
| ブラウザツール | ★★★ | ★★☆ | ★★☆ | コード不要で結合→ピボット分析まで一気にやりたい |
| Excel Power Query | ★★☆ | ★★☆ | ★★☆ | 普段Excelを使っていて追加ツールを入れたくない |
| Python(pandas) | ★☆☆ | ★★★ | ★★★ | 分析の自由度が高く、スクリプトで完全自動化したい |
自分1人で月1回やるだけならPythonが効率的です。チームメンバーにも使ってもらう、あるいはコードを書きたくないなら、ブラウザツールかPower Queryが現実的な選択肢になります。
方法①:ブラウザツールで結合→そのままピボット分析(手軽度★★★)
ブラウザ完結型のCSV分析ツールなら、AhrefsのCSVをドラッグ&ドロップで結合し、そのままピボットテーブルで集計できます。インストール不要で、データがサーバーに送信されることもありません。
たとえばLeapRows(※筆者開発ツール)では、以下の流れで結合から分析まで完結します。
ステップ1: CSVファイルを結合する
CSV結合ツールに、AhrefsからエクスポートしたCSVファイルを複数まとめてドラッグ&ドロップします。多くのツールでヘッダー行の重複は自動で除去され、1つのCSVに統合されます。
結合時にファイル名を識別列として追加できるため、「どのドメインのデータか」「いつエクスポートしたデータか」を結合後も区別できます。
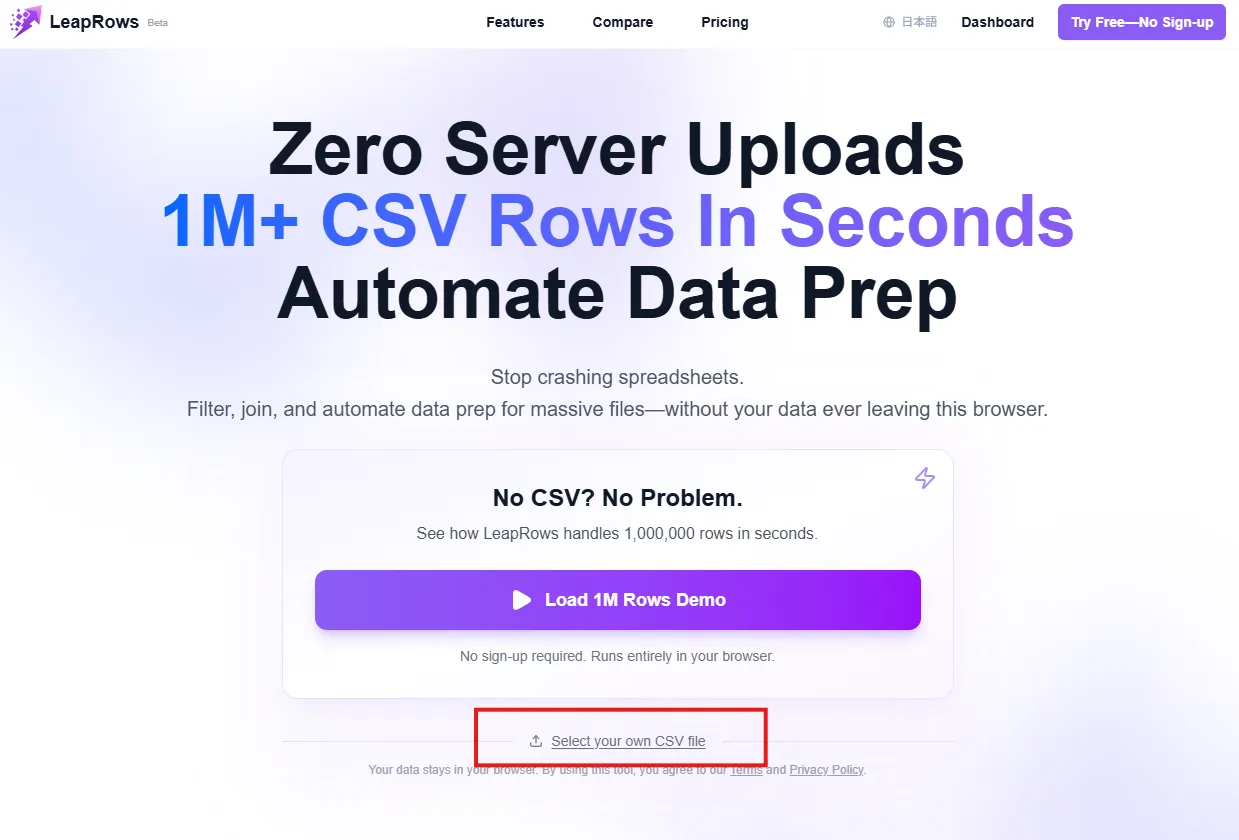
AhrefsからエクスポートしたCSVファイルを複数選択します。
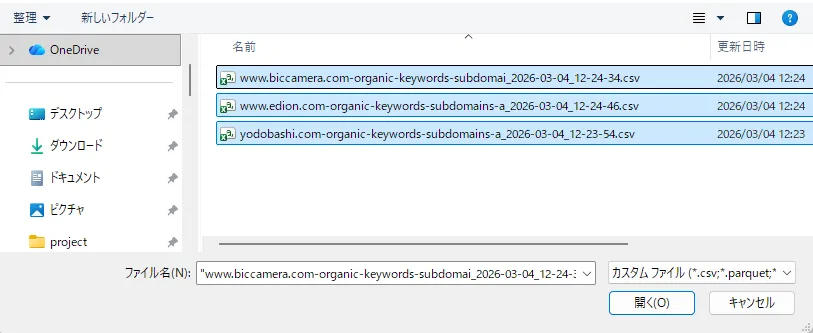
複数CSVが検出されると結合モーダルが表示されるので、「Merge and Save」を選択します。
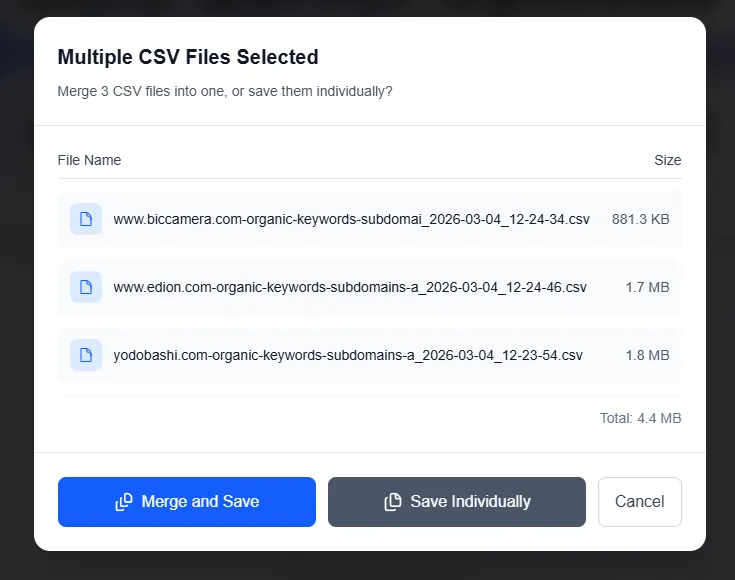
3つのCSVが1つのテーブルに結合されました。
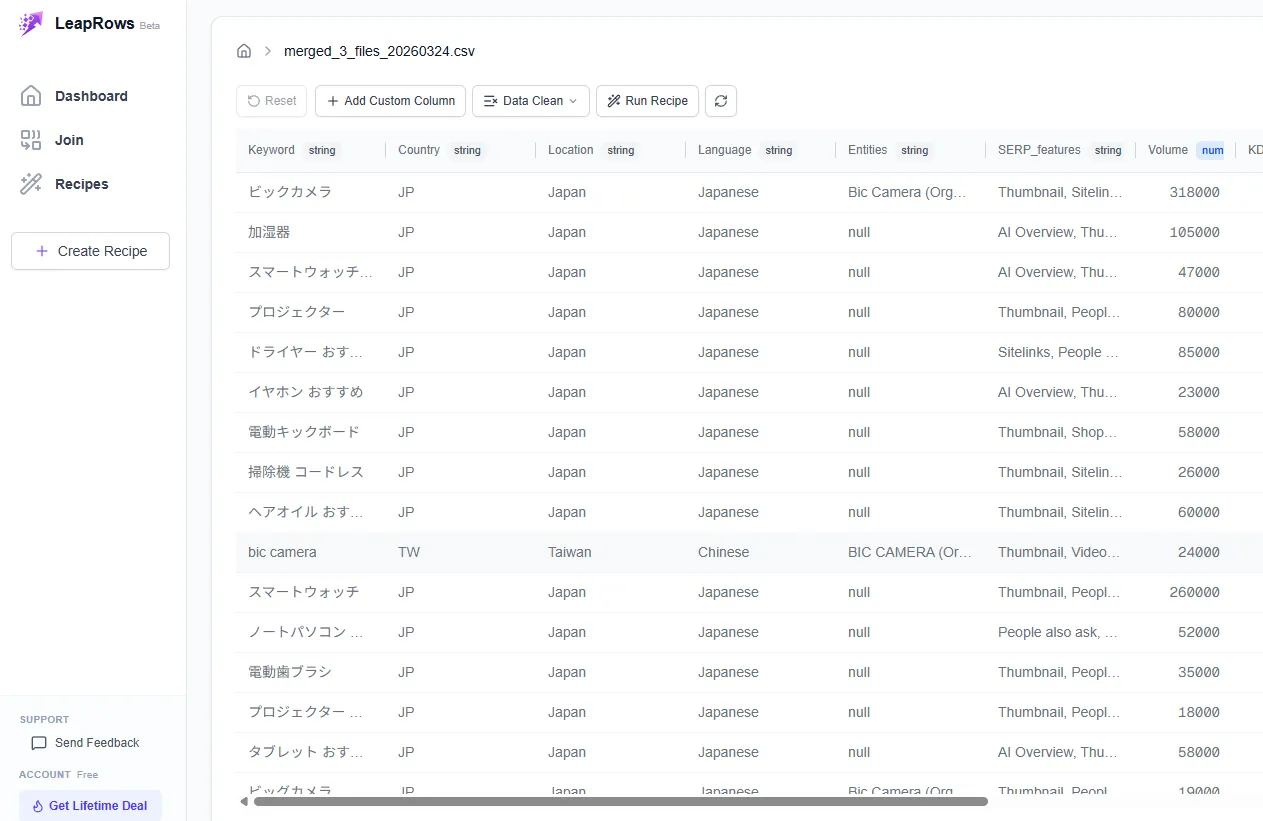
ステップ2: 結合データをピボットで集計する
結合したCSVをそのまま分析画面に渡し、ピボットテーブルを作成します。
- 行: Keyword(キーワード)
- 列: エクスポート日 or ドメイン
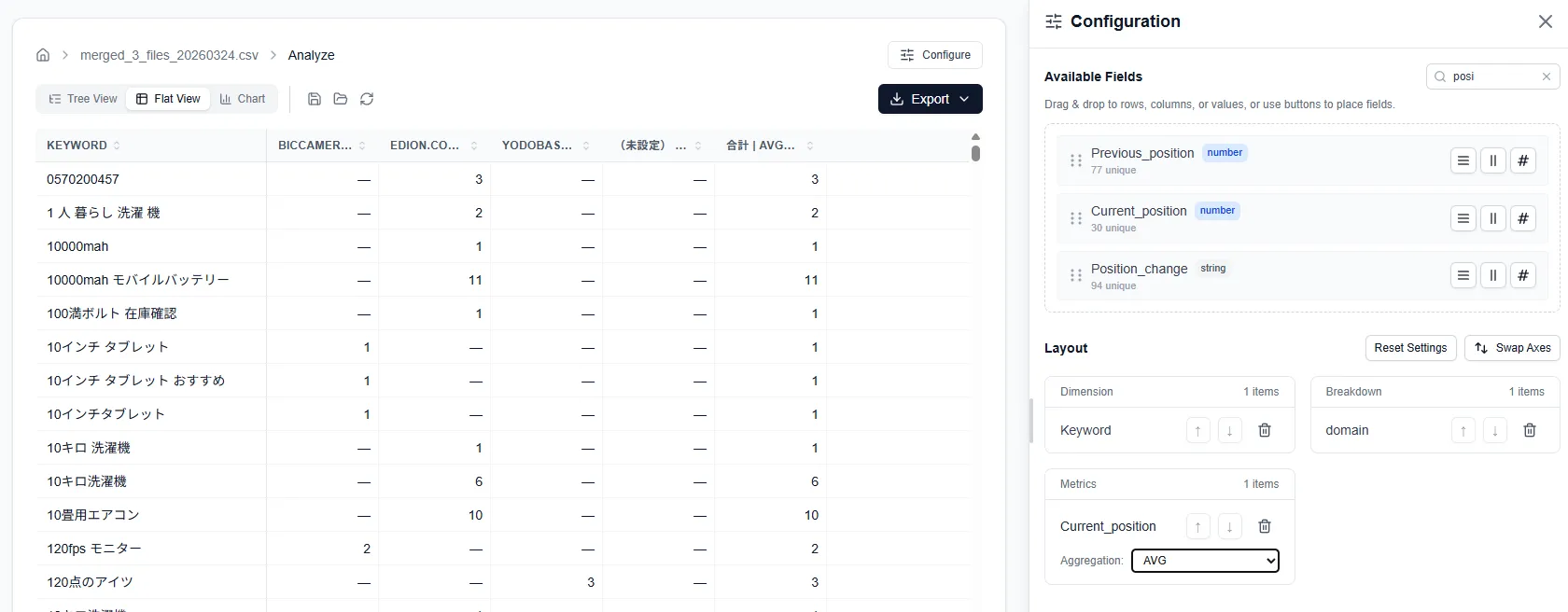
- 値: Position(順位)の平均、Traffic(推定トラフィック)の合計
設定はドラッグ&ドロップで、結果はリアルタイムにプレビューされます。フィルタを追加して「検索ボリューム1,000以上のキーワードだけ」に絞り込むことも可能です。
ステップ3: 結果をエクスポートする
集計結果はCSV・Excelでダウンロードできます。レポート資料に貼る、Looker Studioに渡す、といった後工程にそのまま繋がります。
この方法の最大の利点は、結合・フィルタ・ピボット・エクスポートが1つのツール内で完結することです。ツール間でファイルを受け渡す手間がありません。
方法②:Excel Power Queryで結合する(手軽度★★☆)
ExcelのPower Query機能を使えば、追加ソフトなしでCSVを結合できます。Excel 2016以降であれば標準搭載されています。
手順の概要:
- データ取得: リボンの「データ」タブ →「データの取得」→「ファイルから」→「CSVから」で1つ目のCSVをインポート
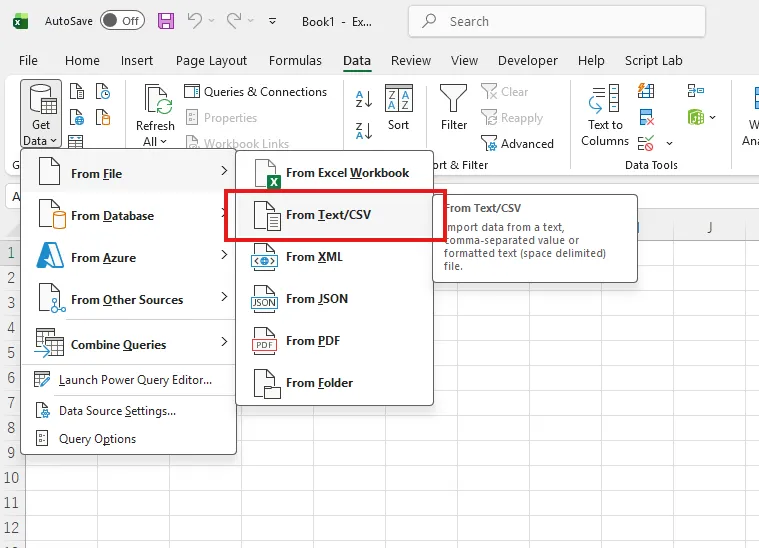
- クエリの追加: 同じ操作で2つ目以降のCSVもインポートし、Power Queryエディター上に複数クエリを作成
- 識別列の追加: 各クエリに「ドメイン名」や「エクスポート日」のカスタム列を追加して、結合後にデータの出所を区別可能に
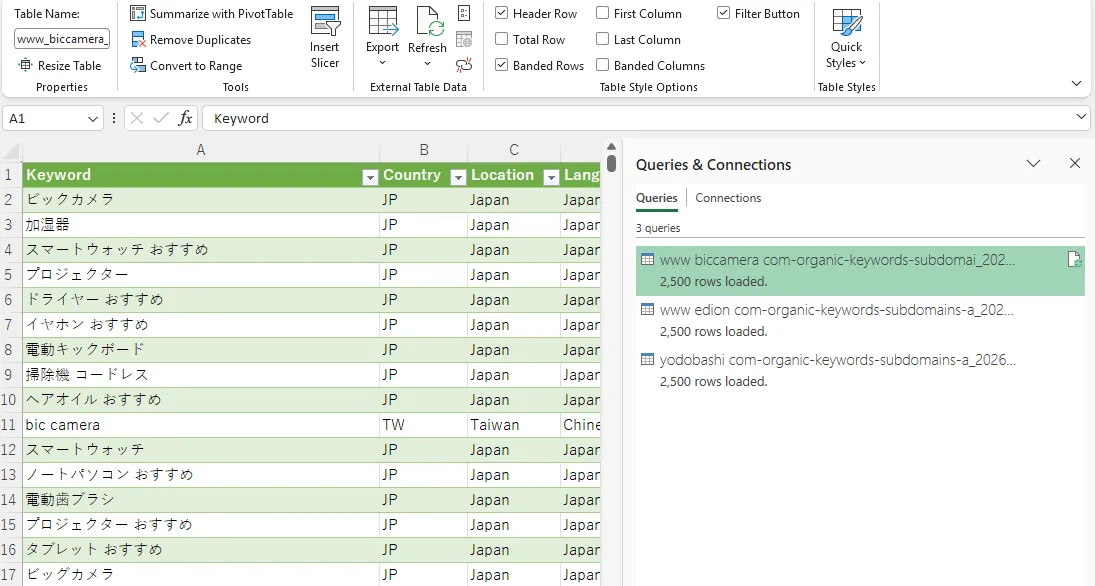
- クエリの結合: 「追加」機能で全クエリを1つのテーブルに統合
- ピボットテーブルで集計: 統合テーブルからピボットテーブルを作成
Power Queryの利点は、データソースへの接続を保持できることです。CSVファイルを更新すれば、「すべて更新」ボタン一つで最新データに反映されます。
ただし、Power Query自体の学習コストはゼロではありません。M言語の記法やステップの概念に慣れるまで、最初の1〜2回は戸惑うかもしれません。また、100万行を超えるCSVはExcelの行数制限にかかるため、事前にフィルタで行数を絞る必要があります。
方法③:Pythonで結合・分析する(手軽度★☆☆)
pandasを使えば、数行のコードでCSVを結合できます。分析の自由度は最も高い方法です。
AhrefsのCSVにはドメインを識別する列が含まれないため、ファイル名から識別列を付与してから結合します。
import pandas as pd
import glob
import os
# ファイルを読み込み、ファイル名からドメイン識別列を付与して結合
files = glob.glob('ahrefs_exports/*.csv')
dfs = []
for f in files:
df = pd.read_csv(f)
# ファイル名からドメイン名を抽出(命名規則: {ドメイン}_organic-keywords_{日付}.csv)
filename = os.path.basename(f)
df['Domain'] = filename.split('_')[0]
df['ExportDate'] = filename.split('_')[2].replace('.csv', '')
dfs.append(df)
combined = pd.concat(dfs, ignore_index=True)
# ドメイン別・キーワード別のトラフィック集計
pivot = combined.pivot_table(
index='Keyword',
columns='Domain',
values='Traffic',
aggfunc='sum'
)
pivot.to_csv('traffic_comparison.csv')
URLごとのトップキーワード抽出のような、より複雑な分析もスクリプトで自動化できます。
# URLごとにTraffic上位5キーワードを抽出
top_keywords = (
combined.sort_values('Traffic', ascending=False)
.groupby('URL')
.head(5)
[['URL', 'Keyword', 'Traffic', 'Position']]
)
Pythonの強みは柔軟性と自動化です。cronやGitHub Actionsと組み合わせれば、毎月のレポート生成を完全自動化できます。
一方で、環境構築(Python + pandas + jupyter)の初期コストと、チームメンバーがコードを読めない場合の属人化リスクは避けられません。「自分1人で定期実行する分析」には最適ですが、チーム全員が触れる仕組みにはなりにくいのが現実です。
結合前に必ずやるべきAhrefsのエクスポート準備
CSVを結合する「方法」だけ知っていても、エクスポートの段階で準備を誤ると、結合後のデータが使い物にならなくなります。
エクスポート対象と行数上限を確認する
Ahrefsのエクスポートボタンは、各レポート画面の右上にあります。主なエクスポート対象は以下の3つです。
| レポート | 主な列 | 用途 |
|---|---|---|
| Organic Keywords | Keyword, Position, Volume, Traffic, URL | キーワード順位・トラフィック分析 |
| Top Pages | URL, Traffic, Keywords | ページ別パフォーマンス分析 |
| Backlinks | Referring Page, DR, Anchor | 被リンク分析 |
エクスポート時に注意すべきは行数上限です。Ahrefsのプランによって、1回のエクスポートで取得できる行数が異なります。上限件数のみがCSVに含まれ、それ以上のデータは出力されません。エクスポート後のCSVの行数がちょうど上限件数になっていたら、データが途切れている可能性を疑ってください。
対処法は2つあります。1つはフィルタで対象を絞ってからエクスポートすること。もう1つは、条件を変えて複数回に分けてエクスポートし、あとで結合することです。
ファイル命名ルールを決めておく
AhrefsのCSVはデフォルトで organic-keywords-example.com-2026-03-13.csv のようなファイル名で保存されます。このままでも使えますが、定期エクスポートを続けるなら、命名規則を統一しておくと結合作業がラクになります。
おすすめの命名パターンは以下です。
{ドメイン}_{レポートタイプ}_{YYYYMMDD}.csv
例:
example-com_organic-keywords_20260313.csvcompetitor-jp_top-pages_20260313.csv
フォルダ構成もセットで決めておくと、Pythonでglobする場合にも、Power Queryでフォルダ読み込みする場合にも便利です。
ahrefs_exports/
├── example-com/
│ ├── organic-keywords_20260101.csv
│ ├── organic-keywords_20260201.csv
│ └── organic-keywords_20260301.csv
└── competitor-jp/
├── organic-keywords_20260101.csv
└── organic-keywords_20260301.csv
ExcelでCSVを「開かない」理由
AhrefsのCSVをExcelで直接ダブルクリックして開くのは避けてください。以下のデータ破壊が起きる可能性があります。
| 問題 | 例 | 影響 |
|---|---|---|
| 検索ボリュームのカンマ | 1,200 が文字列化 | 数値計算不可 |
| 先頭ゼロの消失 | ID列の 0123 が 123 に | データの一致不可 |
| 日付の自動変換 | 1-2 が 1月2日 に | データの変形 |
これらはExcelの「親切な自動変換」が原因ですが、Ahrefsのデータ分析においては害にしかなりません。CSVはExcelで「開く」のではなく、Power Queryで「読み込む」か、ブラウザツールで「アップロードする」ようにしましょう。
結合したAhrefsデータで実践する3つの競合分析
CSVを結合すること自体は手段です。ここからは、結合データを使って何を分析するかを具体的に見ていきます。
キーワード順位の推移比較
最もよく使われるのが、同一キーワードの順位推移を自社と競合で比較する分析です。
必要なデータは、Organic Keywordsレポートを時期をずらして複数回エクスポートしたCSVです。結合後、以下の切り口でピボット集計します。
- 行: Keyword
- 列: エクスポート日(または月)
- 値: Positionの平均
- フィルタ: Volume 1,000以上(検索ボリュームが小さいキーワードを除外)
この集計により、「3ヶ月前は10位だったキーワードが今月5位に上がった」「競合は順位を落としている」といった傾向が一目で分かります。
順位データの推移を見るポイントは3つあります。
- 急上昇しているキーワード: 競合が新規コンテンツを投入した or 既存コンテンツを大幅改善した可能性
- 急降下しているキーワード: アルゴリズムアップデートの影響、またはコンテンツの陳腐化
- 自社と競合で順位が逆転したキーワード: 戦略的に奪還すべきかどうかの判断材料
トラフィック推定値の変化を追う
Ahrefsが算出するTraffic(推定オーガニックトラフィック)は、サイト全体の成長度合いを把握するのに使えます。
Top PagesレポートのCSVを複数時期で結合し、URLグループ単位でトラフィック推移を追跡します。
URLグループ化の方法は、CSVの結合ツールで「カテゴライズ」機能を使うのが手軽です。たとえば、URLに /blog/ を含む行を「ブログ」、/product/ を含む行を「商品ページ」としてラベル付けし、グループ別にTrafficを合計します。
この分析で見えてくるのは、「競合はブログ経由のトラフィックが前年比2倍に伸びている」「商品ページのトラフィックは横ばい」といった戦略の重心です。自社の注力領域を決める判断材料になります。
獲得キーワードのギャップ分析
自社と競合のOrganic Keywords CSVを結合すると、「競合が獲得しているが自社にはないキーワード」を抽出できます。これがコンテンツギャップ分析です。
Ahrefsのダッシュボード上でも「Content Gap」機能は使えますが、CSV結合で行うメリットがあります。
- 複数競合を一度に比較できる: 3社分のCSVを結合すれば、3社それぞれとのギャップを1つのテーブルで確認できます
- フィルタの自由度が高い: 検索ボリューム、順位、トラフィックなど複数条件でフィルタリングできます
- 分析結果を保存・共有できる: CSVでエクスポートして、チームのタスク管理ツールに渡せます
具体的な操作は、結合データを「Keyword」でピボットし、列に「ドメイン」、値に「Position」を入れます。自社のPositionが空で、競合のPositionに値が入っているキーワードが、獲得すべきギャップキーワードです。
毎月の分析を効率化するテンプレート活用
Ahrefsのデータ分析は、1回やって終わりではありません。毎月、あるいは四半期ごとにエクスポートして、同じ切り口で比較し続けることに意味があります。
テンプレートで定型分析をワンクリック化する
毎回同じ操作を手動で繰り返すのは非効率です。「CSVを結合する → フィルタで絞り込む → ピボットで集計する」という一連の操作をテンプレートとして保存しておけば、次回は新しいCSVをアップロードするだけで同じ分析が再現されます。
| 方式 | ツール | メリット | 制限 |
|---|---|---|---|
| テンプレート型 | ブラウザ完結ツール | コード不要・チームメンバーも実行可 | ツール依存 |
| スクリプト型 | Python | 完全自動化・柔軟 | メンテナンスコスト・属人化リスク |
ブラウザ型ツールの中には、この「操作の記録と再生」をレシピテンプレートとして保存できるものがあります(ツールによって機能の有無が異なるため、選定前にご確認ください)。
チーム共有とレポート出力
分析結果は、最終的に誰かに見せるものです。チーム内の週次ミーティング、クライアントへの月次レポート、経営層への四半期報告——いずれも、生データではなく「集計済みの表やグラフ」が求められます。
ピボット集計の結果をCSVやExcelでエクスポートすれば、そのままスライドに貼れます。Looker StudioやTableauに渡す場合も、ピボット前の結合データ(フラットなCSV)をそのまま接続すれば使えます。
ここで押さえておきたいのは、分析の再現性です。「先月のレポートと同じ切り口で今月も出してほしい」と言われたとき、手順を覚えている人がいないと詰みます。テンプレート化しておけば、誰が実行しても同じ結果が得られます。
まとめ
AhrefsのCSVを結合して分析する方法を整理しました。
- 結合方法は3つ: ブラウザツール(手軽・ノーコード。LeapRows ※筆者開発ツール など)、Power Query(Excel内で完結)、Python(柔軟・自動化向き)。チーム構成とスキルレベルに合わせて選んでください
- エクスポート準備が分析品質を決めます: 行数上限の確認、ファイル命名ルールの統一、ExcelでCSVを直接開かないこと。この3点を守るだけで、結合後のトラブルは大幅に減ります
- 結合はゴールではなく手段です: 本当に価値があるのは、結合データから引き出す「キーワード順位の推移」「トラフィックの変化」「コンテンツギャップ」といったインサイトです
- 定期分析はテンプレート化しましょう: 毎月同じ操作を繰り返すなら、テンプレートに保存して工数を削減。チームメンバーも使える仕組みにしておけば、分析が属人化しません
Ahrefsのデータは「エクスポートして終わり」にするにはもったいないものです。CSVを結合して、競合との差分を定量化して、次の打ち手を考える。そのプロセスを、できるだけ手間なく回せる方法を選んでください。